Keep your stack
Point existing OpenAI, Anthropic, or supported Gemini workflows at a local proxy instead of rebuilding the whole integration path.
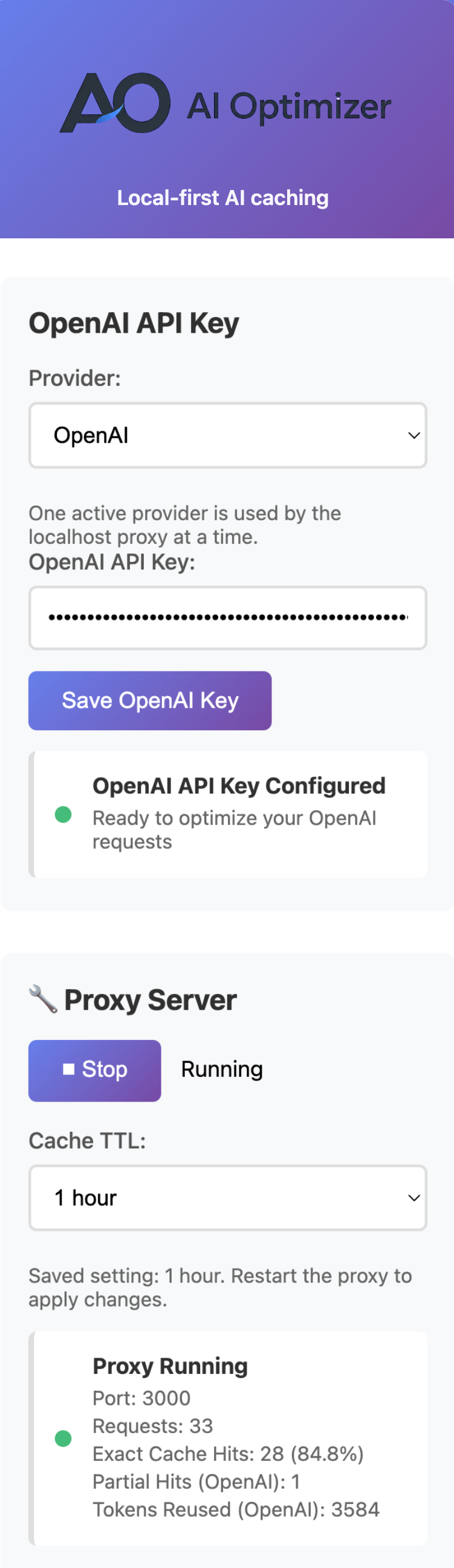
AI Optimizer is a local-first desktop app that reduces repeated OpenAI, Anthropic, and Google Gemini API spend by adding a caching proxy on localhost. It works best for repeat-heavy scripts, agents, tools, and automations that send the same or very similar requests over time.
Repeated API work gets expensive fast, and most teams want a way to control it without rewriting the workflow around a new product.
Point existing OpenAI, Anthropic, or supported Gemini workflows at a local proxy instead of rebuilding the whole integration path.
Cache duplicate and recurring requests so repeat traffic stops hitting the API at full cost.
Track requests, cache hits, and usage patterns in one place instead of guessing where the waste lives.
The adoption path stays simple: route traffic locally, cache repeat work, and see the result clearly.
Point your workflow at AI Optimizer on localhost.
Repeated work can resolve without paying full price every time.
See requests, cache hits, and provider usage in one local control layer.
AI Optimizer earns trust with clear setup, visible cache behavior, and a workflow that fits into the tools you already use.
Teams move faster when the product fits into existing operations instead of demanding a big rebuild.
Keep cost visibility close to the workflow rather than waiting for a billing surprise.
Requests, cache hits, and compatibility proof are stronger than inflated marketing claims.
Use the homepage for the quick value story, then let the deeper pages carry technical proof and implementation detail.
Install AI Optimizer, connect your workflow, and start reducing wasted OpenAI, Anthropic, and Google Gemini spend without changing how your team already works.